What do people do in data science
Originally posted on 24 October 2017, at: https://blog.gramener.com/what-do-people-actually-do-when-they-say-they-do-data-science/
On a daily basis, I notice a lot of misconceptions regarding the field of data science. A lot of this is due to the ever evolving mechanics of the field. I will skip the standard definitions (think mathematics, statistics, machine learning, software) of what Data Science means since others have covered it well enough (Links section below) and will touch upon different aspects of data science.
1) Engineering
Engineering involves setting up the infrastructure, tools and products.
a) Infrastructure
Infrastructure refers to setting up of servers and configuring them for your optimal use, setting up version control, access controls. This is not vastly different from the existing technology infrastructure setup at software firms.
b) Tools
Establishing a tools pipeline early-on will ease the product development. The material that continuously assists your team to develop rapidly are what I refer to tools. These include: the design approach (+ supporting software), choice of your text editor, default programming language (+ supporting software), version control, testing practices. Notice that some of this can be automated.
c) Products
The development of products is an evolving process with solutioning. Once the solution is identified (at this stage the solution is very much a prototype — very glitchy) it has to be productionized (used by clients or making it open for public use — minimal glitches).
2) Solutioning
The type of problem, of course, varies from scenario to scenario. The problem of predicting the weather for the next 4 days is different from classifying the type of flowers which is again different from creating a dashboard to consume sales across regions.
Designing a solution involves understanding business requirements, designing the workflow, creating a development pipeline, software testing, and productionizing.
Here by solution, I refer to an output that is consumed by an end user (business clients, general audience). The exact solutioning will vary across projects. A solution that handles, say, 100 MB of data isn’t necessarily valuable for a 5GB data. A solution that handles flat files (CSV) won’t be valid for the ones that fetch data from remote databases. Bring in authentication, authorization, security at the least you will have a lot of variation in solutions.
A machine learning (ML) solution would use a trained model and test using real-time data (think real-time Tweet classification). This solution requires identifying a ML algorithm, creating a feature space (using Twitter data post data gathering, cleaning, analysis), training a ML model which will be used to test real-time data.
Given the variation, not every solution can be a product. If features are abstracted enough to work well for multiple scenarios you have a product.
3) Communication
Much of the communication here, as any other field, occurs as part of internal reports, talks, seminars.
If you are an academic you will share the results as part of a journal or conference or a workshop publication.
If you are in a corporate environment, you will likely share the results with clients in a web view (dashboard) or a slide deck.
If you are an independent investigator (ex: citizen data scientist), you will likely share the analysis via a blog post.
All approaches will involve carefully created visuals to narrate the story and results. It is critical to remember that the audience in each of the cases is different. Trained academics write publications for other trained academics. Corporate workers create results for business clients. Citizen data scientists write analysis for journalists, other investigators.
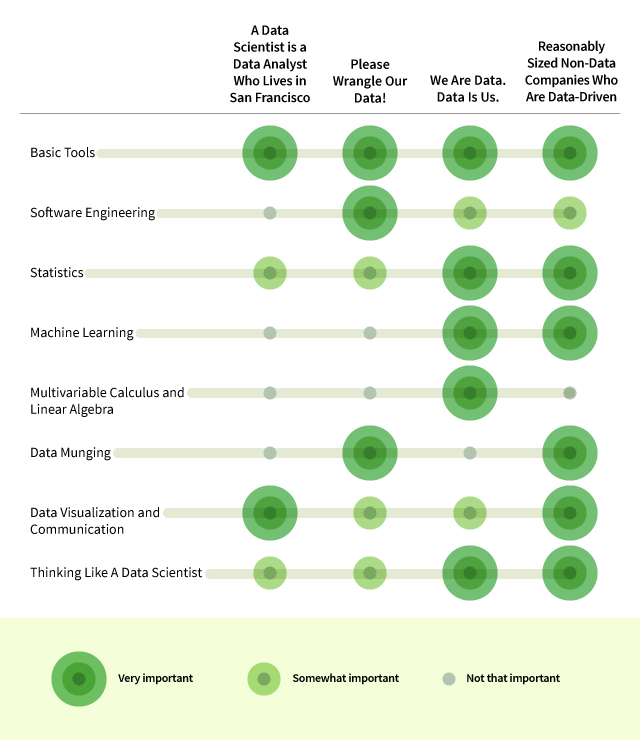
Image credit: Udacity [e]
In a gist, a variety of skills are useful to be a data scientist: data (gathering, cleaning, analysis, visualization), modeling (machine learning algorithms), statistics (understanding causality, accuracy metrics), software engineering (efficiency, quality assurance). The overlap of these skills in an individual will depend on the team size (individual vs small or medium or large organization). The breadth (software engineering, data processing, ML etc.) of the skills is as important as depth (understanding the mathematics behind ML algorithms or different statistical techniques) — you can only improve it over time.
If you are working on any of the cogs above, you are contributing to the wheel of data science. Don’t let anyone tell you otherwise.
Links:
a) Trey Causey, Getting started in data science
b) University of Wisconsin, What do data scientists do?
c) KDNuggets, What is Data Science, and What Does a Data Scientist Do?
d) Hillary Mason, What is a Data Scientist?
e) Udacity, Data Science Job Skills